Seamless Database Ingestion
From Connection to Insight
Extract, load, and analyze data from leading databases with minimal configuration. Secure, scalable, and built on your own infrastructure.
Our three-step process to ingest data from any source.
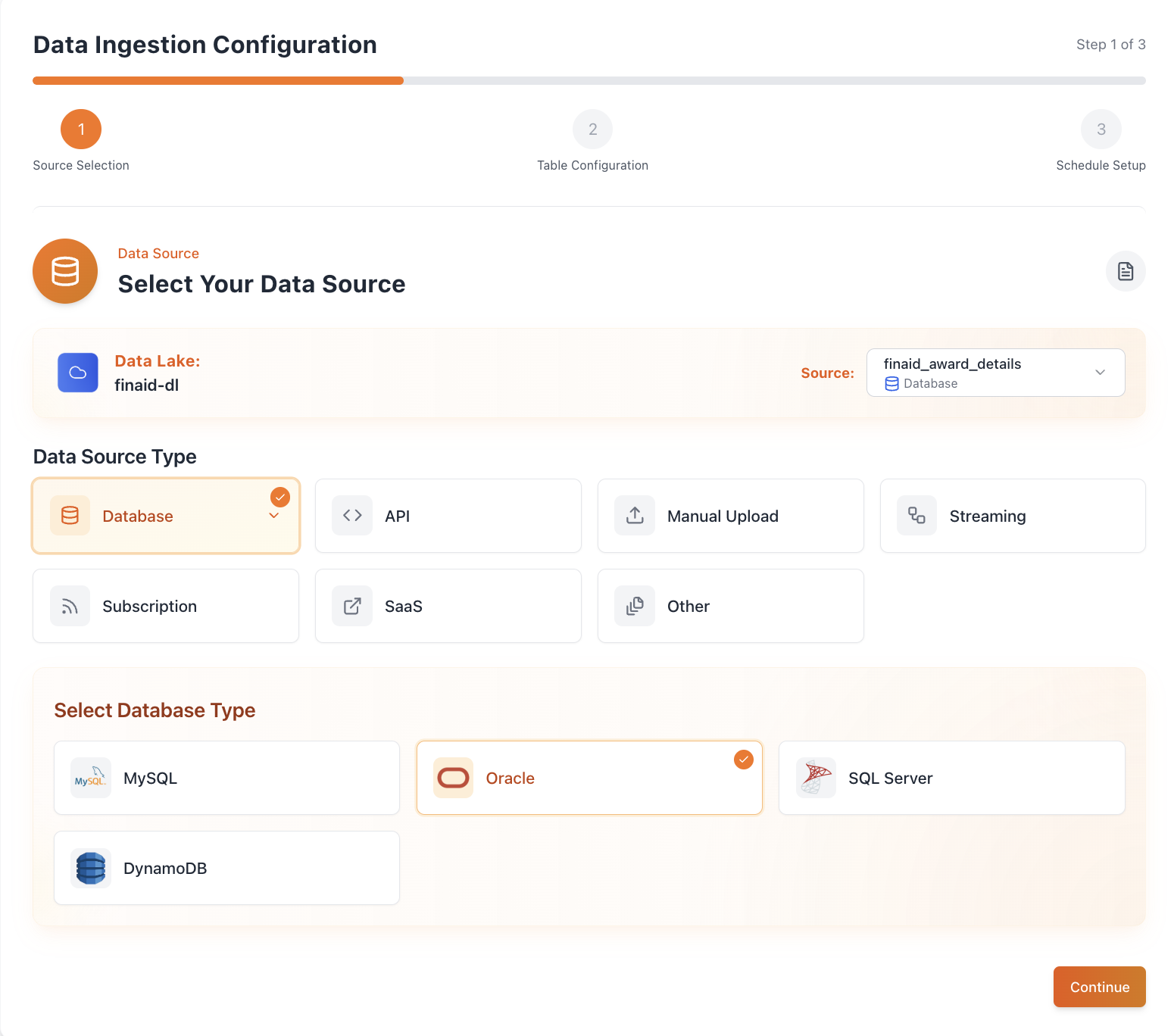
Step 1: Choose Your Source
Connect structured or unstructured data from anywhere — databases, APIs, files, SaaS apps, streams, and more. Autolake supports a wide range of sources to help you build a unified lake in minutes.
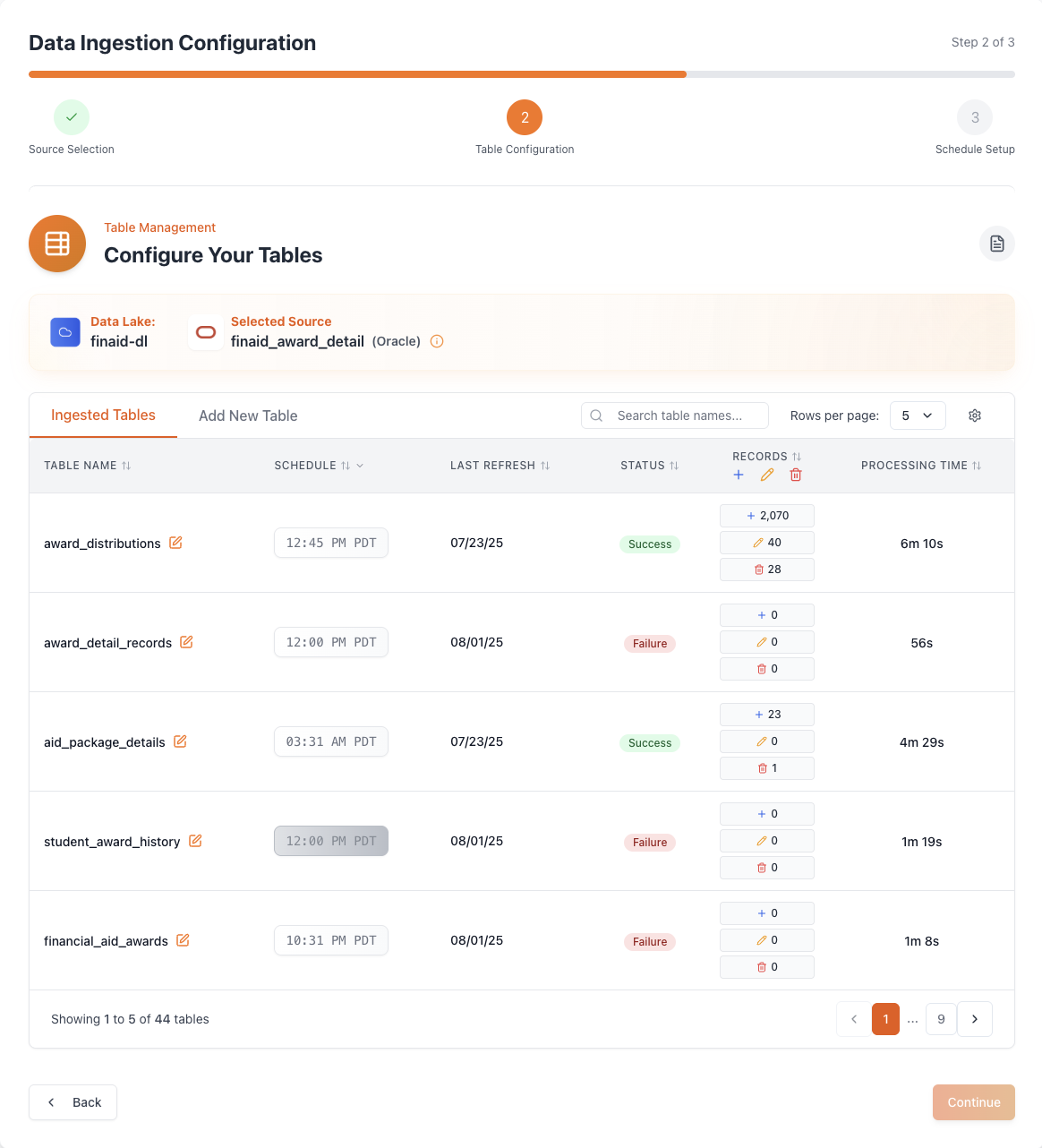
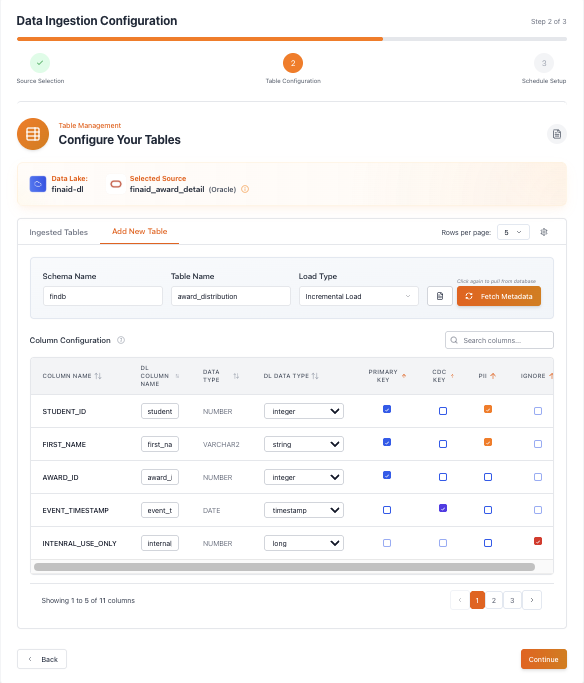
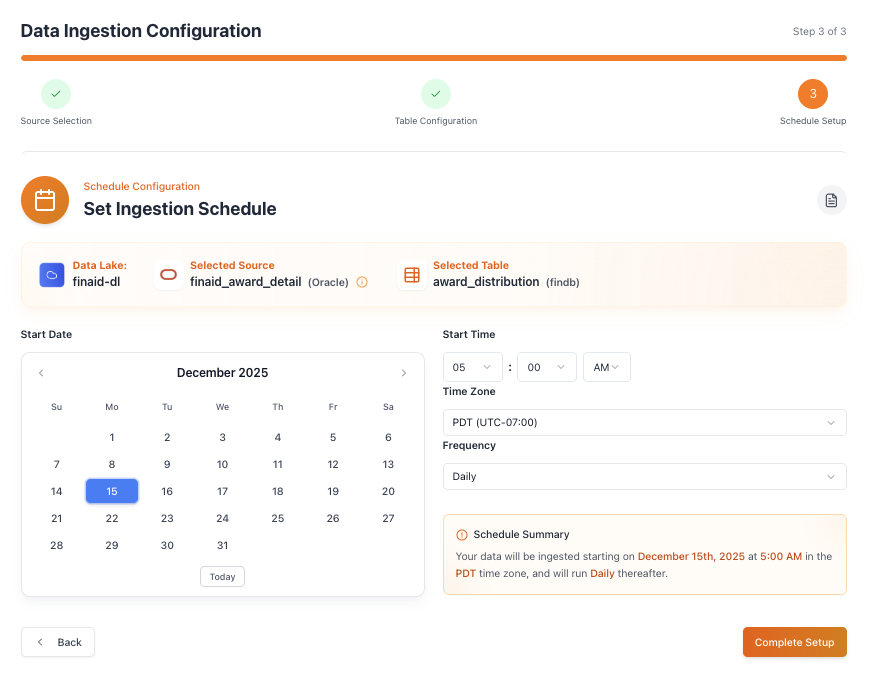
And just like that, your data is ready!
With Autolake's intuitive pipeline, you've successfully set up your data ingestion in just three simple steps. Your data is now flowing seamlessly into your data lake, ready for analysis and insights.
Data Lake Process Flow
Compare Autolake's streamlined approach with traditional complex data integration processes.
Source Systems
Ingestion
Processing
Analytics
Consumption
Autolake Advantages
- Streamlined 5-step process vs. 9+ traditional steps
- 95% faster implementation time
- Automated schema detection and mapping
- Automatic data catalog generation
- Automatic data profiling
- Automatic data obfuscation
- Automatic data migration
- Automatic data replication
- Automatic data encryption
- Automatic data deduplication
- Automatic anomaly detection
- Automatic pipeline generation
Detailed Benefits by User Type
Discover how Autolake transforms data workflows for every role in your organization
Data Scientists
Access and analyze raw data through SQL queries, enabling advanced analytics without complex data preparation steps.
Key Features
- Single access point for raw data
- SQL-based data cataloging
- Iterative analysis without data preparation
Real-World Examples
- Run SQL queries on raw data instantly
- Build ML models with clean data
- Analyze trends without preparation delays
Data Engineers
Build reliable data pipelines with flexible extraction options and guaranteed data integrity.
Key Features
- Full & incremental extraction options
- Action-based record identification
- Primary key enforcement
Real-World Examples
- Reduce pipeline development by 60%
- Automate schema detection
- Monitor data quality in real-time
Data Consumers
Gain immediate access to trusted data sources through a self-service model, enabling faster business decisions.
Key Features
- Transparent access to raw data
- Single source of truth
- Self-service insights
Real-World Examples
- Create dashboards without IT assistance
- Make data-driven decisions 40% faster
- Access trusted data from one platform
Stakeholders
Optimize costs with a pay-per-use model while ensuring proper governance and compliance.
Key Features
- Cost-effective, pay-per-use model
- Data Lake as a Service approach
- Enhanced governance and compliance
Real-World Examples
- Reduce infrastructure costs by 50%
- Achieve ROI within 3-6 months
- Meet regulatory requirements
Standards-based data connectors
The most comprehensive collection of data drivers. Anywhere.

Adobe Analytics
Analytics

Adobe Marketo Engage
Marketing

Amazon Aurora
Database

Amazon DocumentDB
Database

Amazon DynamoDB
Database

Amazon OpenSearch Service
Search

Amazon Redshift
Data Warehouse

Asana
Project Management

Azure Cosmos
Database

Azure SQL
Database

Binary
File Format

Blackbaud
CRM

Get started
Stop building pipelines. Start asking questions.
See it live on your own sources — a 30-minute walkthrough with a founding engineer. No prep needed.